%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Computer Graphics

A Diffusion Approach To Radiance Field Relighting Using Multi Illumination Synthesis
This method involves creating relightable radiance fields by leveraging priors extracted from 2D image diffusion models. The approach can convert multi-view data captured under single lighting conditions into a dataset with multi-illumination effects, represented through 3D Gaussian splats for relightable radiance fields. This method does not rely on precise geometric shapes and surface normals, making it well-suited for handling cluttered scenes with complex geometries and reflective BRDFs.
AI image generation
51.9K
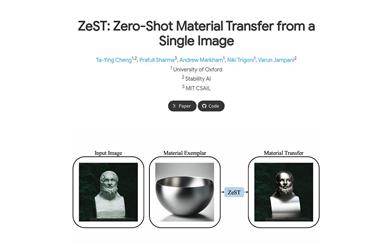
Zest
ZeST is an image material transfer technology co-developed by the research teams of the University of Oxford, Stability AI, and MIT CSAIL. It enables the transfer of materials from one image to another object without any prior training. ZeST supports single material transfer and can handle multi-material editing within a single image. Users can easily apply one material to multiple objects in an image. In addition, ZeST also supports fast image processing on devices, eliminating the dependence on cloud computing or server-side processing, significantly improving efficiency.
AI image editing
87.2K

Animatabledreamer
AnimatableDreamer is a framework for generating and reconstructing animatable non-rigid 3D models from single-eye videos. It is capable of creating non-rigid objects of different categories while adhering to the object movement extracted from the video. The key technology is the proposed canonical score distillation method, which simplifies the generation dimension from 4D to 3D, performs denoising across different frames in the video, and carries out the distillation process within a unique canonical space. This ensures consistent generation and realistic morphologies across different postures. With differentiable deformation, AnimatableDreamer elevates the 3D generator to 4D, providing a new perspective on the generation and reconstruction of non-rigid 3D models. Additionally, combining with the inductive knowledge of consistency diffusion models, canonical score distillation can regularize reconstruction from new perspectives, thereby enhancing the generative process in a closed loop. Extensive experiments demonstrate that this method can generate highly flexible 3D models guided by text from single-eye videos, while achieving superior reconstruction performance compared to typical non-rigid reconstruction methods.
AI 3D tools
59.6K

Paint3d
Paint3D generates high-resolution, unlit, and diverse 2K UV texture maps for untextured 3D meshes, and performs conditional generation based on text or image inputs. It first generates a rough texture map by creating view-dependent images with a pre-trained 2D diffusion model that considers depth information and then performs multi-view texture fusion. Subsequently, it employs specialized UV completion and UVHD texture models to remove the lighting effects and fill in incomplete areas. Paint3D can produce semantic-consistent, unlit 2K UV textures, significantly enhancing the texture generation quality of untextured 3D objects.
AI image generation
109.6K
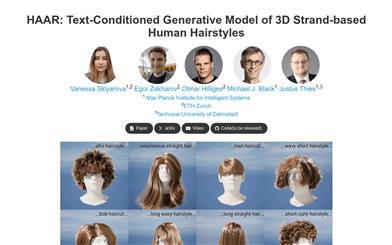
HAAR
HAAR is a text-input based generation model capable of generating realistic 3D hairstyles. It takes text prompts as input and generates 3D hairstyle assets ready for various computer graphics animation applications. Unlike current AI-based generation models, HAAR utilizes 3D hair strands as the foundation representation. It automatically annotates the generated synthetic hairstyle model using a 2D visual question answering system. We propose a text-guided generation method that uses a conditional diffusion model to generate guided hair strands in the latent hairstyle UV space and reconstructs a dense hairstyle containing hundreds of thousands of hair strands using a latent upsampling process given a textual description. The generated hairstyles can be rendered using existing computer graphics techniques.
AI design tools
56.0K
Featured AI Tools
Chinese Picks

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
149.6K
Fresh Picks

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
112.6K
English Picks

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
131.1K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
99.4K
English Picks

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
65.7K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
90.0K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
661.3K
Chinese Picks

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M